
现在本地创建一个excel表,使用以及两个sheet,读写具体数据如下:
sheet1:
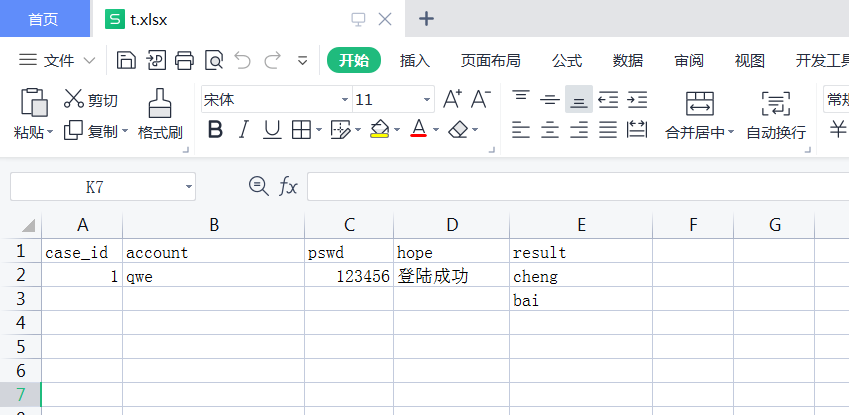
sheet2:
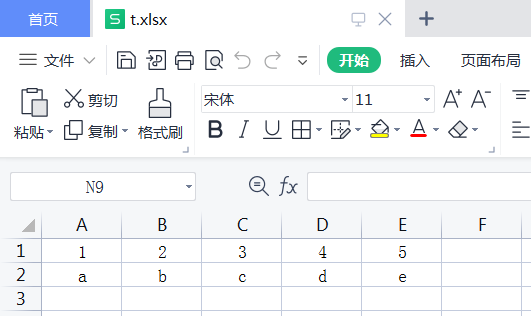
读取excel文件
pandas.read_excel(io,使用 sheet_name=0, header=0, names=None, index_col=None, usecols=None)
io:excel文件路径。
sheet_name:返回指定的读写sheet。
header:表头,使用默认值为0。读写也可以指定多行。使用当header取值为None时候data打印值最多,读写0相比None会少一行,使用1对比0又会在少一行。读写也就是使用说设置header为多少,那么那行之前的读写数据就会缺失。header也可以设置为一个范围值如header=[0,使用 1]表示前两行为多重索引。
usecols:读取指定的读写列。
skiprows:跳过特定行。使用
import pandasa = pandas.read_excel("t.xlsx",sheet_name=0)#sheet_name可以使用下标,sheet的名称print(a) #打印所有print(a.values) #打印除第一行以外的信息print(a.values[0]) #打印第一行的值print(data['标题列'].values) #打印具体一列的值#读取同一文件的不同sheetdata= pandas.read_excel("t.xlsx", ['Sheet1', 'Sheet2'])print(data)#打印sheet1和sheet2的所有元素print(data.get('Sheet1')['result'][0]) #打印sheet1表的result列的第一个元素#sheet_name = None时,返回所有表的数据data = pandas.read_excel("t.xlsx", sheet_name=None)print(data)结果:"""{ 'Sheet1': case_id account pswd hope result0 1.0 qwe 123456.0 登陆成功 cheng1 NaN NaN NaN NaN bai, 'Sheet2': 1 2 3 4 50 a b c d e}"""#sheet_name可以选择名称,下标组合方式提取多张表数据data = pandas.read_excel("t.xlsx", sheet_name=['Sheet1',1])print(data)结果:"""{ 'Sheet1': case_id account pswd hope result0 1.0 qwe 123456.0 登陆成功 cheng1 NaN NaN NaN NaN bai, 1: 1 2 3 4 50 a b c d e}"""#查询指定列的数据data = pandas.read_excel('t.xlsx', sheet_name='Sheet1', usecols=['result',])print(data)结果:""" result0 cheng1 bai"""data = pandas.read_excel('t.xlsx', sheet_name='Sheet1', usecols=[0])print(data)结果:""" case_id0 1.01 NaN"""data = pandas.read_excel('t.xlsx', sheet_name='Sheet1', usecols=[0, 1])print(data)结果:""" case_id account0 1.0 qwe1 NaN NaN"""ExcelFile:为了更方便地读取同一个文件的多张表格
import pandas#同时读取一个文件的多个sheet,仅需读取一次内存,性能更好data = pandas.ExcelFile("t.xlsx")sheets = pandas.read_excel(data)#sheet_name不写,默认为查第一个sheet的数据sheets = pandas.read_excel(data, sheet_name="Sheet2")#查看指定sheet的数据print(sheets)#也可以这么写with pandas.ExcelFile("t.xlsx") as xlsx: s1 = pandas.read_excel(xlsx, sheet_name="Sheet1") s2 = pandas.read_excel(xlsx, sheet_name="Sheet2")print(s1)print("-----------------------")print(s2)结果:""" case_id account pswd hope result0 1.0 qwe 123456.0 登陆成功 cheng1 NaN NaN NaN NaN bai----------------------- 1 2 3 4 50 a b c d e""""""index_col:索引对应的列,可以设置范围如[0, 1]来设置多重索引na_values:指定字符串展示为NAN"""with pandas.ExcelFile('t.xlsx') as xls: data['Sheet1'] = pandas.read_excel(xls, 'Sheet1', index_col=None, na_values=['NA']) data['Sheet2'] = pandas.read_excel(xls, 'Sheet2', index_col=1) print(data) print("-------------------------------") print(data['Sheet1']) print("--------------------------------") print(data['Sheet2'])结果:"""{ 'Sheet1': case_id account pswd hope result0 1.0 qwe 123456.0 登陆成功 cheng1 NaN NaN NaN NaN bai, 'Sheet2': 1 3 4 52 b a c d e}------------------------------- case_id account pswd hope result0 1.0 qwe 123456.0 登陆成功 cheng1 NaN NaN NaN NaN bai-------------------------------- 1 3 4 52 b a c d e"""写入文件:
将数据写入excel
1.当文件不存在时,会自动创建文件,并写入数据;
2.当文件存在时,会覆盖数据;
3.sheet_name 不写默认为Sheet1;
4.文件写入,切记关闭excel。
data = { '名字': ['张三','李四'], '分数': [100, 100] }a= pandas.DataFrame(data)a.to_excel('1.xlsx', sheet_name='Sheet1',index=False)# index = False表示不写入索引excel一次写入多sheet:
1.下面代码为在1.xlsx中写入sheet1,sheet2两个表。
2.可以通过在ExcelWriter中添加mode参数,该参数默认为w,修改为a的话,可以在已存在sheet的excel中添加sheet表。
df1 = pandas.DataFrame({ '名字': ['张三', '王四'], '分数': [100, 100]})df2 = pandas.DataFrame({ '年龄': ['18', '19'], '性别': ['男', '女']})with pandas.ExcelWriter('1.xlsx') as writer: df1.to_excel(writer, sheet_name='Sheet1', index=False) df2.to_excel(writer, sheet_name='Sheet2', index=False)#新增一个sheetdf3 = pandas.DataFrame({ '新增表': ['1', '2']})with pandas.ExcelWriter('1.xlsx', mode='a') as writer: df3.to_excel(writer, sheet_name='Sheet3', index=False)















